Active Frame, Location, and Detector Selection for Automated and Manual Video Annotation
Abstract
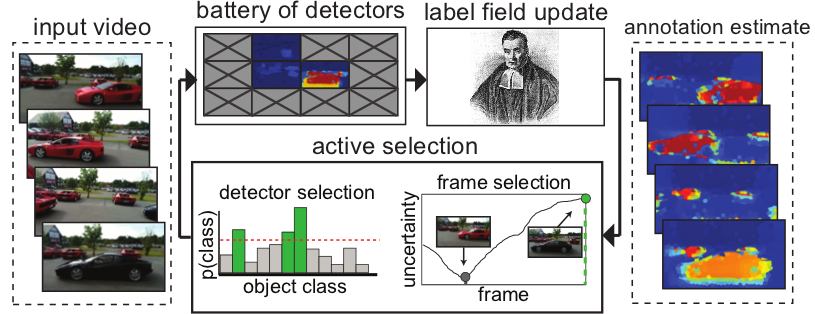
We describe an information-driven active selection approach to determine which detectors to deploy at which location in which frame of a video shot to minimize semantic class label uncertainty at every pixel, with the smallest computational cost that ensures a given uncertainty bound. We show minimal performance reduction compared to a "paragon" algorithm running all detectors at all locations in all frames, at a small fraction of the computational cost. Our method can handle uncertainty in the labeling mechanism, so it can handle both "oracles" (manual annotation) or noisy detectors (automated annotation).
Overview
Results
Several video examples of the ''baseline'' (all frames labeled without temporal consistency) and our approach (using 20% frames and temporal consistency) can be seen below.
Additionally, below we show several still frames.

Code and dataset
MATLAB implementation of the algorithms described in the paper and data can be downloaded here (320 Mb).
To evaluate our approach we use video sequences from Human-Assisted Motion [1], ViSOR [2], MOSEG [3], Berkeley Video Segmentation [4], as well as additional videos from Flickr. Frames from these sequences are shown below. Pixelwise ground truth annotations and frames from our sequences can be downloaded here (240 Mb).
Note that the ''Flickr'' videos were downloaded from the internet, and may be subject to copyright. We do not own the copyright and only provide the images for non-commercial research purposes.

If you use this work in your research, please cite our paper:
- V. Karasev, A. Ravichandran and S. Soatto
Active Frame, Location, and Detector Selection for Automated and Manual Video Annotation
In CVPR, 2014.@inproceedings{karasevRS14, author = {Karasev, V. and Ravichandran, A. and Soatto, S.}, title = {Active Frame, Location, and Detector Selection for Automated and Manual Video Annotation}, booktitle = {CVPR}, year = {2014}, month = {June}
References
C. Liu, W. T. Freeman, E. H. Adelson, and Y. Weiss. Human-assisted motion annotation. In CVPR, 2008
R. Vezzani and R. Cucchiara. Video surveillance online repository (ViSOR): an integrated framework. Multimedia Tools Appl., 2010.
T. Brox and J. Malik. Object segmentation by long term analysis of point trajectories. In ECCV, 2010
P. Sundberg, T. Brox, M. Maire, P. Arbelaez, and J. Malik. Occlusion boundary detection and figure/ground assignment from optical flow. In CVPR, 2011.
Please report problems with this page to Vasiliy Karasev.