Vasiliy KarasevI am a staff software engineer at Waymo where I work on perception for autonomous driving.
Previously, I spent several years doing computer vision at Zoox.
I did my PhD at UCLA, and was advised by Prof. Stefano Soatto.
My work revolved around ''value of information'' / decision making problems, optimization, and their applications in computer vision.
|

|
Publications |
Misc |

|
Intent-Aware Long-Term Prediction of Pedestrian MotionV. Karasev, A. Ayvaci, B. Heisele, and S. Soatto ICRA, 2016 video / details / pdf / bibtex Forecasting what pedestrians intend to do is easier if they behave rationally. We show how this assumption simplifies motion prediction in the assisted/autonomous driving setting. |

|
Causal video object segmentation from persistence of occlusionsB. Taylor, V. Karasev, and S. Soatto CVPR, 2015 (oral) video / details / pdf / bibtex We show how to exploit occlusions to discover salient objects in video. |
|
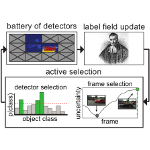
Active frame, location, and detector selection for automated and manual video annotationV. Karasev, A. Ravichandran, and S. Soatto CVPR, 2014 video / details / pdf / bibtex How to choose where and which detectors to run (or m-turks to query), if we can run only a few of them? We answer this question using the ‘‘information gathering’’ framework, and show results on semantic video segmentation. |
|
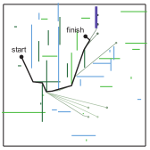
Controlled recognition bounds for visual learning and explorationV. Karasev, A. Chiuso, and S. Soatto NIPS, 2012 pdf / bibtex We show how to (greedily) search for an unknown object, under occlusions, quantization-scale, and uncertain measurements. |
|
Temporal presentation protocols in stereoscopic displays: flicker visibility, perceived motion, and perceived depthD. Hoffman, V. Karasev, and M. Banks Journal of the Society for Information Display, 2011 pdf / bibtex We studied how different 3D display presentation methods affect flicker, motion artifacts, and errors in perceived depth. |
|
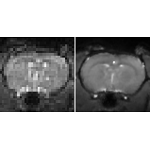
High resolution fMRI using compressed sensing2011 details / pdf This was my MS project. |
|
Design and source code from Leonid Keselman's adaptation of Jon Barron's website |